Kafka實戰指引 駕馭實時海量流式數據處理
在當今數據驅動的時代,實時處理海量數據流已成為企業構建敏捷業務、實現即時決策的核心能力。Apache Kafka,作為一個高吞吐、可水平擴展的分布式流處理平臺,正是在這一背景下脫穎而出的關鍵技術。本文將提供一份實戰指引,幫助您理解并運用Kafka進行高效的實時數據處理。
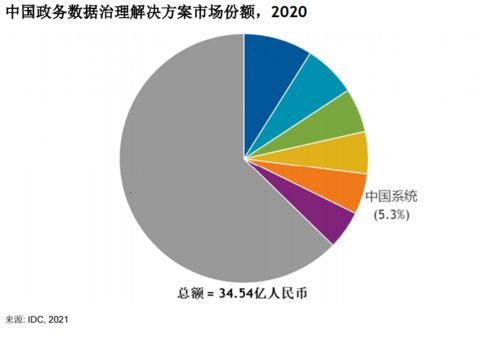
一、 Kafka核心概念與架構
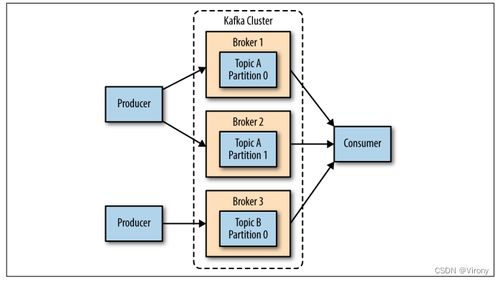
要駕馭Kafka,首先需理解其核心模型。Kafka以“主題”(Topic)為數據分類單位,生產者(Producer)將消息發布到特定主題,消費者(Consumer)則訂閱這些主題以拉取消息。數據持久化在分布式、分區的“日志”(Log)中,確保了消息的順序性和可重播性。其集群由多個代理(Broker)組成,通過ZooKeeper(或Kraft模式下的自管理元數據)進行協調,共同保障高可用性與容錯性。這種簡潔而強大的架構,正是其支撐海量數據流的基石。
二、 實戰:構建實時數據處理流水線
- 數據采集與注入:利用Kafka Connect或自定義Producer,輕松集成數據庫變更日志、應用日志、IoT設備數據、用戶行為事件等多種數據源,將數據作為流實時注入Kafka主題。
- 流式處理與轉換:這是數據處理的核心環節。可以借助Kafka原生的Streams API或與Flink、Spark Streaming等流處理框架集成。在此階段,您可以進行豐富的數據操作:
- 過濾與清洗:剔除無效或噪聲數據。
- 轉換與豐富:將數據格式標準化,或通過查找外部數據源(如維表)補充上下文信息。
- 聚合與窗口計算:例如,計算每分鐘的網站點擊量、每小時的交易總額或滑動窗口內的用戶活躍度。這些實時聚合結果本身又可作為新的數據流發布到Kafka。
- 數據分發與下沉:處理后的結果流,可以通過消費者應用程序實時推送到儀表盤進行可視化告警,或通過Kafka Connect的Sink連接器寫入下游系統,如數據倉庫(ClickHouse、Hive)、搜索引擎(Elasticsearch)、緩存(Redis)或其它數據庫,供進一步分析與服務調用。
三、 處理海量數據的關鍵實戰技巧
- 性能調優:根據實際負載調整生產者的批量提交大小、壓縮算法,消費者的拉取批次大小與間隔。合理設置主題的分區數,以并行度換取吞吐量。
- 容錯與 Exactly-Once 語義:合理配置生產者確認機制(acks)和消費者的偏移量提交策略。利用Kafka Streams或集成框架的事務支持,在流處理中實現端到端的精確一次處理,確保計算結果在故障恢復后不重不丟。
- 監控與運維:密切監控集群健康度(Broker負載、網絡IO、磁盤使用)、主題流量(消息進出速率、積壓量)以及消費者組的滯后情況。利用Kafka自帶的指標和外部監控系統(如Prometheus)構建儀表盤,以便快速發現瓶頸與異常。
- 資源規劃與安全:根據數據吞吐量和保留策略規劃存儲容量。在生產環境中,務必配置SSL/TLS加密、SASL認證和基于ACL的授權,保障數據安全。
四、 典型應用場景
Kafka的實時數據處理能力在眾多場景中大放異彩:實時推薦系統依據用戶即時行為更新推薦結果;金融風控系統對每筆交易進行毫秒級欺詐檢測;物聯網平臺處理億萬設備上報的傳感器數據并觸發實時告警;企業級數據中臺構建統一、高效的實時數據管道。
掌握Kafka實戰,意味著您擁有了構建低延遲、高可靠實時數據系統的強大工具。從理解其核心原理出發,通過精心設計的數據流水線,結合性能調優與穩健的運維實踐,您將能從容應對海量流式數據的挑戰,釋放實時數據的巨大業務價值。記住,成功的實時處理系統始于一個穩定、高效的數據流中樞,而Kafka正是這一角色的卓越擔當。
如若轉載,請注明出處:http://m.yyzxmr.cn/product/11.html
更新時間:2026-05-22 12:27:47